
- 들어가기에 앞서, 불명확한 내용이거나 틀린 내용이 존재할 수 있습니다.
KinectFusion?
kinectfusion은 2011년에 마이크로소프트 리서치 팀에서 낸 논문이다. 총 두 가지 버전이 있지만, 거의 같은 내용을 다룬다. 특히 하나는 실제 application에 특화된 내용을 다룬다.
일단 여기에서는 먼저 이론적인 내용을 다룬 Kinectfusion : Real-Time Dense Surface Mapping and Tracking 에 대해 다루고자 한다.
먼저, 논문의 목적과 input / output에 대하여 알아보자.
해당 논문은 kinect 카메라로부터 얻는 정보(pixel당 매칭되는 depth, RGB color = RGB-D)으로부터 실제 공간의 object들과 background를 3d reconstruction하는 것이다. 그 형태는 3차원 mesh라고 처음에는 생각했었는데, 다시 살펴보니 volumetric representation인 것 같다. 렌더링을 수행할 때 pixel당 ray를 쏴서 ray tracing을 사용하여 진행하는데 그 과정에서 tsdf(Truncated Signed Distance Function)을 사용하므로 그렇게 표현되는 것 같다. 아니.. 애초에 tsdf 방식을 사용하므로 volumetric represectation이 될 수밖에 없겠다.
그 밖에 중요한 특징은
- 이 논문의
output은3d dense surface model이다.- 생각해보면
voxel마다tsdf가 계산되고 렌더링이 수행되니까 sparse하지 않고 dense한 것은 당연하다.
- 생각해보면
- Real-time에 이뤄지는 구현 방식이다.
- 사실 읽기 전에도 그렇고
voxel마다 연산이 이뤄지는 것을 생각하면 의아하다. 계산량이 많을 텐데 어떻게 real-time 내에 처리되지..? 라고 의문을 가질 수 있다..ㅎㅎ - 결론적으로, 그래서 상대적으로 공간이 협소한 내부에서만 굴릴 수 있고 외부에서는 도저히 real-time 내에는 굴리기가 불가능하다. (그 외에 태양광 같은 issue도 있지만..)
- 사실 읽기 전에도 그렇고
하여튼, 논문의 전체적인 pipeline은 다음과 같다.
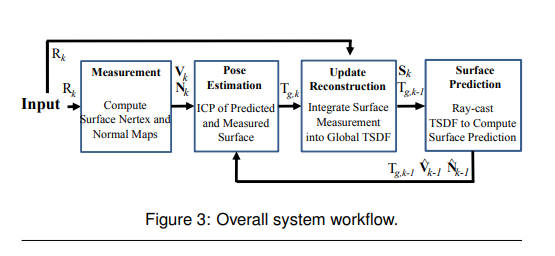
먼저 RGB-D 정보에서 depth 정보만 input으로 넣으면 카메라 공간에서의 vertex와 normal map을 뽑아낼 수 있게 된다.(이미지에서는 Nertex라고 오타가 난 듯..)
- 물론 RGB-D 정보에서 바로 뽑아낼 수 있는 것은 vertex map이고 normal map은 해당 pixel과 인접 pixel 간의 depth vector로 approximation을 하여 계산된다.
그렇게 된다면 이제 이전 frame에서의 vertex와 normal map을 사용해야 할 때다. 우리는 3d reconstruction을 위해 vertex와 normal map을 camera space가 아닌 world space로 옮겨서 계산해야 할 필요가 있다. 그럴려면 매 frame당 camera space에서 world space로 가는 변환 행렬을 알아내야 한다. 그를 위해서는 또 world space에서 camera의 6dof 행렬을 알아야 한다.어떻게 알 수 있을까?
ICP 알고리즘을 두 frame 간의 vertex와 normal map 간에 적용시켜 알 수 있다. 물론 전 frame의 camera의 6dof 행렬을 안다는 전제 하에서 가능하다. ICP 알고리즘 자체가 각 frame 간의 겹치는 object에서 카메라가 얼마나 움직였나를 알아내어 결과적으로는 world space에서의 카메라 6dof 행렬을 뽑아내는 것이므로 원래 6dof를 알아야 차이를 계산 가능하겠다.
그 다음 camera의 6dof 행렬을 알게 되었으면 그 말은 world space에서 camera가 어느 위치와 회전 정도에 있는지 안다는 것이고, world space에서 object들의 vertex와 normal map도 안다는 소리이다. 이제 Rendering이 가능한 것인데, 이걸 volumetric representation으로 표현하는데 surface 중심으로 해당 voxel이 얼마나 떨어져 있냐를 나타내는 tsdf 방식으로 값을 매긴다.
그것이 끝났으면 실제로 surface 중심으로 reconstruction을 수행한다. 각 voxel마다 해당 정보가 담겨 있으므로 우리는 그냥 카메라에 찍힌 2차원 image에서 각 pixel에서 ray를 쏘아서 reconstruction을 하면 된다. 이게 매 frame마다 반복된다. 끝이다 ㅎㅎ
overview는 단순한 것 같지만 세부적으로 파고들어가면 쓰인 방법들의 detail이 쉽지만은 않다.
detail은 시간이 될 때 마저 작성할 계획이다.
# kinectfusion : Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera
kinect 자매품 논문이다. 앞 논문이 이론적 배경과 수식 위주로 설명했다면 이 논문은 실제 application, 활용 분야, 구현 technique에 초점을 맞춘 논문이며 그에 따라 사진 설명도 많고 난이도는 kinect 1 논문보다는 덜한 것 같아 다행이다.
## applications
- object segmentation
- reconstruction된 3D Model 상에서 가상의 object와 함께
physis simulation가능
09.11 작성중(미완)



댓글남기기