
- 들어가기에 앞서, 불명확한 내용이거나 틀린 내용이 존재할 수 있습니다.
elasticFusion?

이전에 다루었던 kinectfusion과는 사뭇 다른 논문이다.
논문 제목에 fusion이라는 단어가 붙는 것은 동일하지만 kinectfusion은 실세계 물체를 어떻게 3D로 reconstruction할 것인가에 대한 논문이었고, elasticfusion은 SLAM과 같이 주위 환경을 RGB-D 카메라로 찍고 돌아다니면서 해당 이미지들을 프레임별로 input으로 받아 mapping과 해당 map 상에서의 camera pose tracking을 할 것인지에 대한 논문이다.
기존 SLAM 관련 논문과의 차이점
기존 SLAM은 camera의 trajectory 최적화에 focus를 맞추었다면, elasticfusion은 mapping되는 map 최적화에 focus를 맞추었다고 볼 수 있다.
또한, surfel이라는 vertex에 normal vector가 딸린 자료구조를 사용한다.
active model / inactive model
frame마다 누적되면서 생성되는 모델은 다음과 같이 두 파트로 나누어지는 듯하다.
active modelinactive model
loop closure는 이전에 카메라가 방문했던 곳을 revisit하면 그때마다 active model과 inactive model을 align하여 진행되는 것 같다.
Deformation graph
deformation graph라는 그래프를 매 프레임마다 생성한다.
이 그래프는 쉽게 말해서, 컴퓨터 그래픽스 시간에 배웠던 rigging을 생각하면 된다.
기억을 되살려보면, character animation을 simluation할 때, character의 각 뼈가 주축이 되고, 그 뼈 주위에 위치한 vertex는 얼마나 해당 뼈에 가까운지의 척도로 weight가 설정되어 주위 뼈가 움직인 정도를 weighted sum으로 받아 움직이게 되었다.
이 deformation graph의 각 node들이 뼈에 mapping되고, 해당 node들 주위에 위치하는 surfel들이 vertex에 mapping되는 것이다.
아래 그림을 보면 더 이해가 잘 간다. 유튜브 영상의 한 캡쳐본이다.
https://www.youtube.com/watch?v=BEEN7Dmo9vI
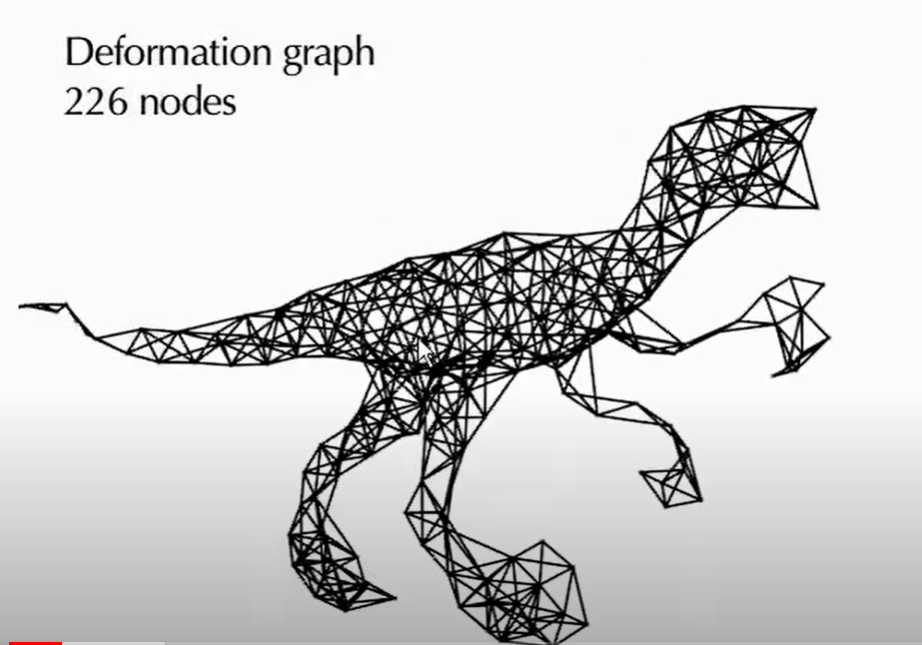
위 그림에서 저 철사(?)들이 deformation graph이다. 각 모서리들이 node고, 각 node를 잇는 철사들이 edge라는 것을 알 수 있다.
매 프레임마다 갱신되는 이 그래프로 surfel map을 갱신한다.
그런데, graph의 node마다 영향을 주게 되는 surfel이 달라지게 되고 이 관계를 tracking하게 된다.
알게 된 것들
RGB-D카메라로 촬영되므로, 매 frame의 측정되는 data는 depth map $D$와 colour map(RGB) $C$이다.- 이 매 frame마다 측정되는 두 가지 data가 global surfel map에
fuse되면서 surfel map이 갱신된다.
notation
- $D^{a}_{t}$ : t frame의
active set의 depth map - $D^{i}_{t}$ : t frame의
inactive set의 depth map
의문들
photometric pose란 정확히 무엇인가?- 논문을 읽어보면, 각 frame Image의 pixelwise한 intensity들의 차를 summation한 것이라고 추측
- 물론, 각 frame의 camera pose도 estimation되므로 2차원 → 3차원 → 2차원의 변환 과정을 거쳐 측정됨


댓글남기기